|
I'm a third-year PhD student at ZJU, advised by Prof.Wenguan Wang and Prof.Yi Yang. I got my B.S. from SSE, Tongji Univ. in 2020. |

|
|
I'm interested in Machine Vision and Embodied AI. Feel free to contact me if there is any question on my research. |
|
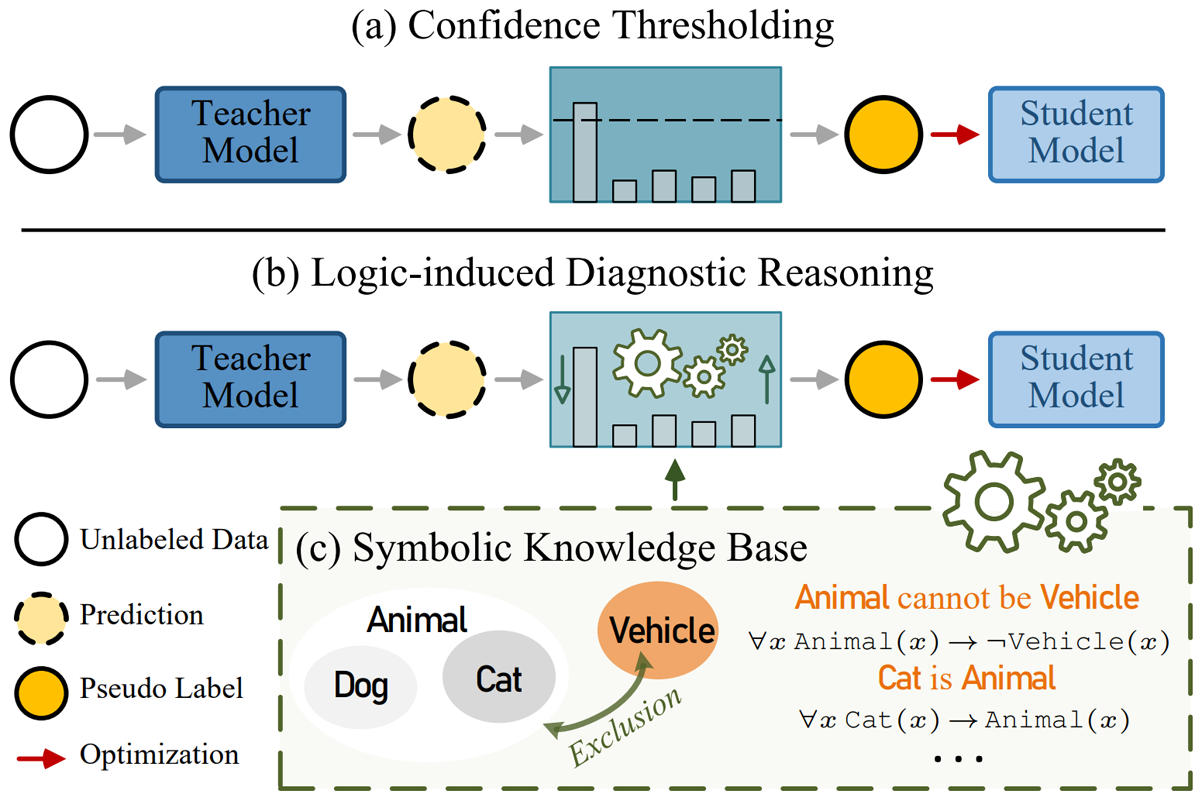
Chen Liang, Wenguan Wang, Jiaxu Miao, Yi Yang ICCV, 2023 arXiv / video / code LogicDiag identifies conflicts in pseudo labels using symbolic knowledge and resolves them through logic-induced diagnoses. This approach improves performance by correcting erroneous labels and reducing error accumulation. |
|
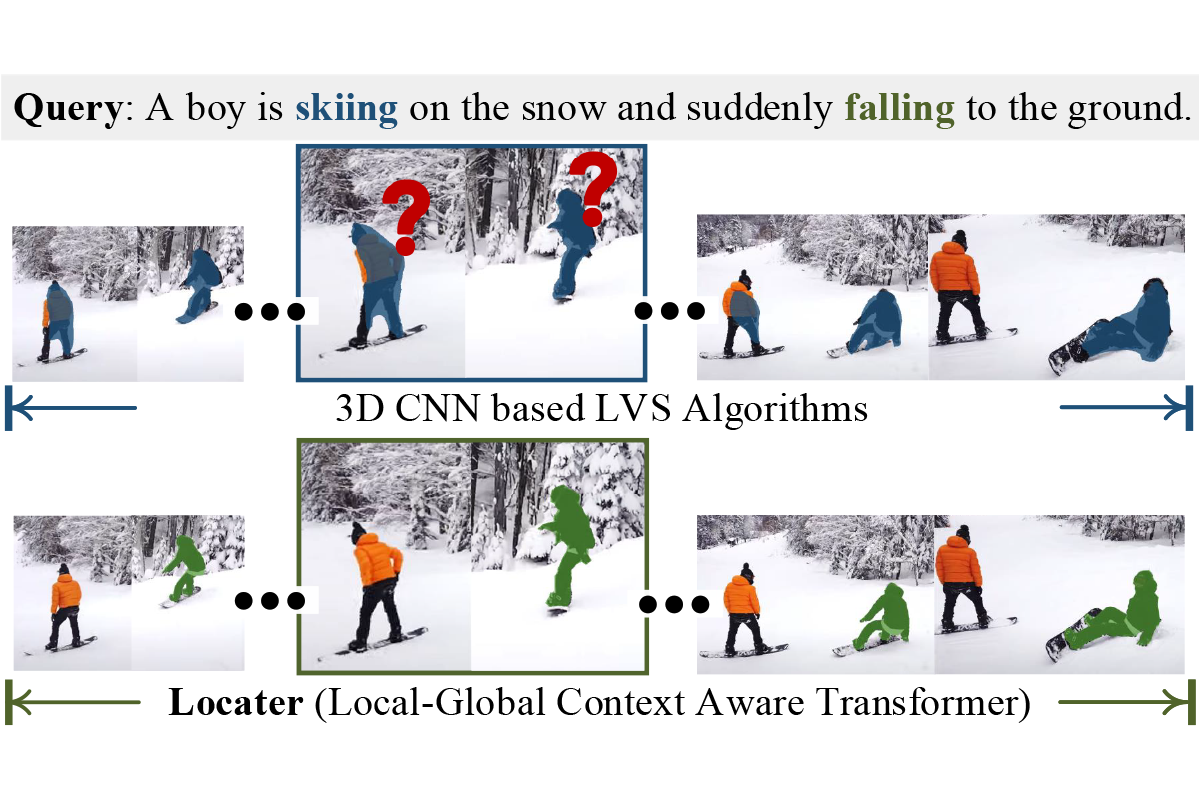
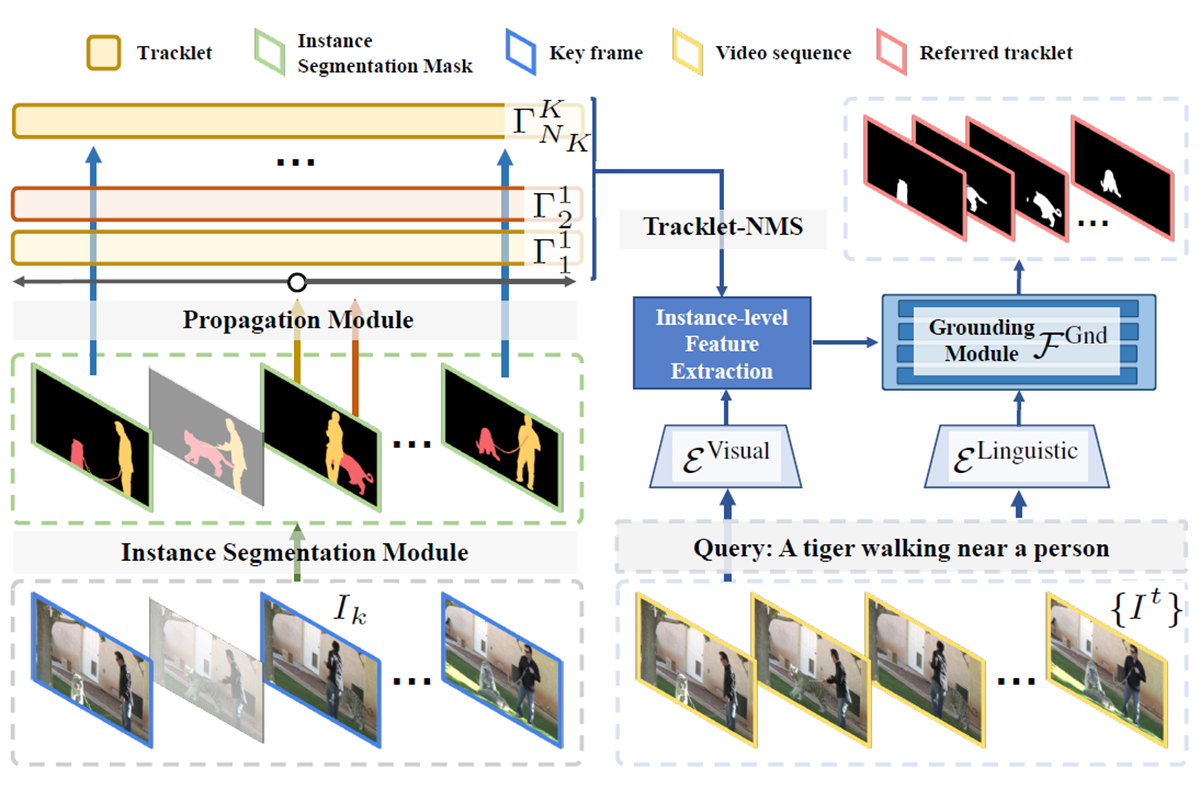
Chen Liang, Wenguan Wang, Tianfei Zhou, Jiaxu Miao, Yawei Luo, Yi Yang TPAMI, 2023 arXiv / dataset / code A new model that incorporates finite memory to align both the short-term and long-term video context with the language expression in an efficient manner. |
|
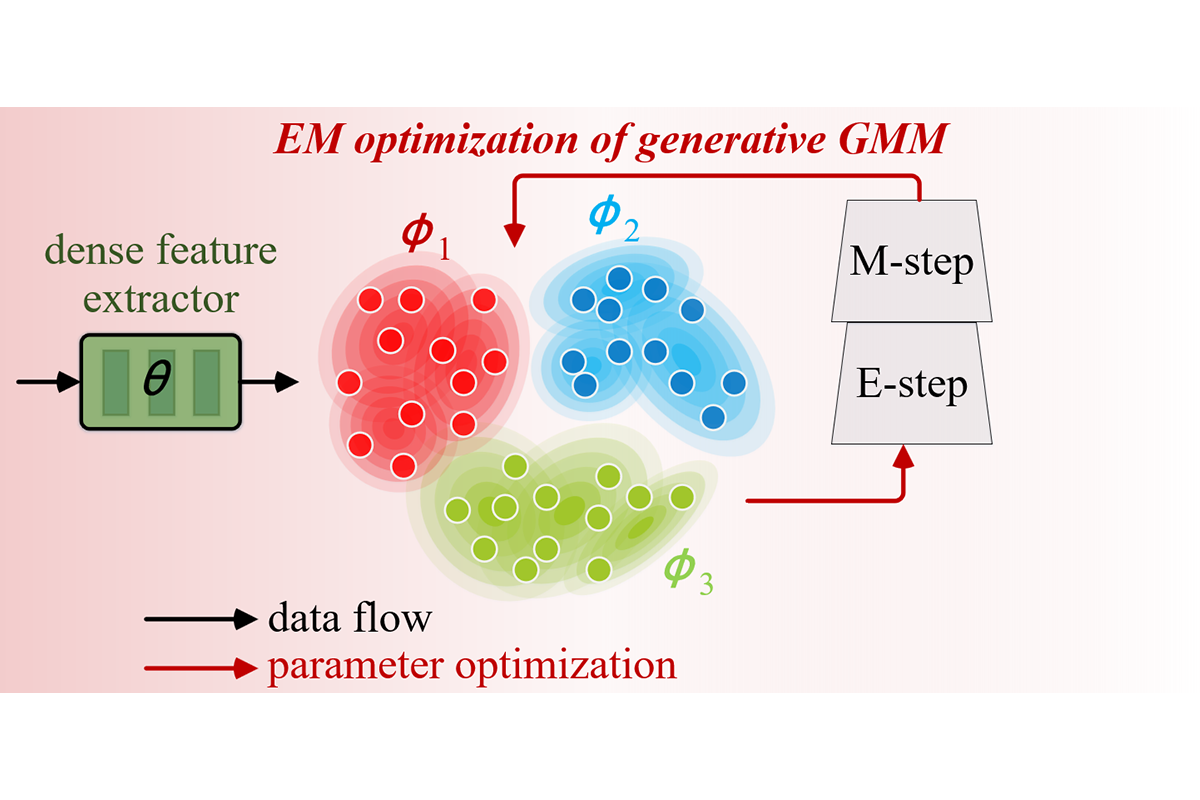
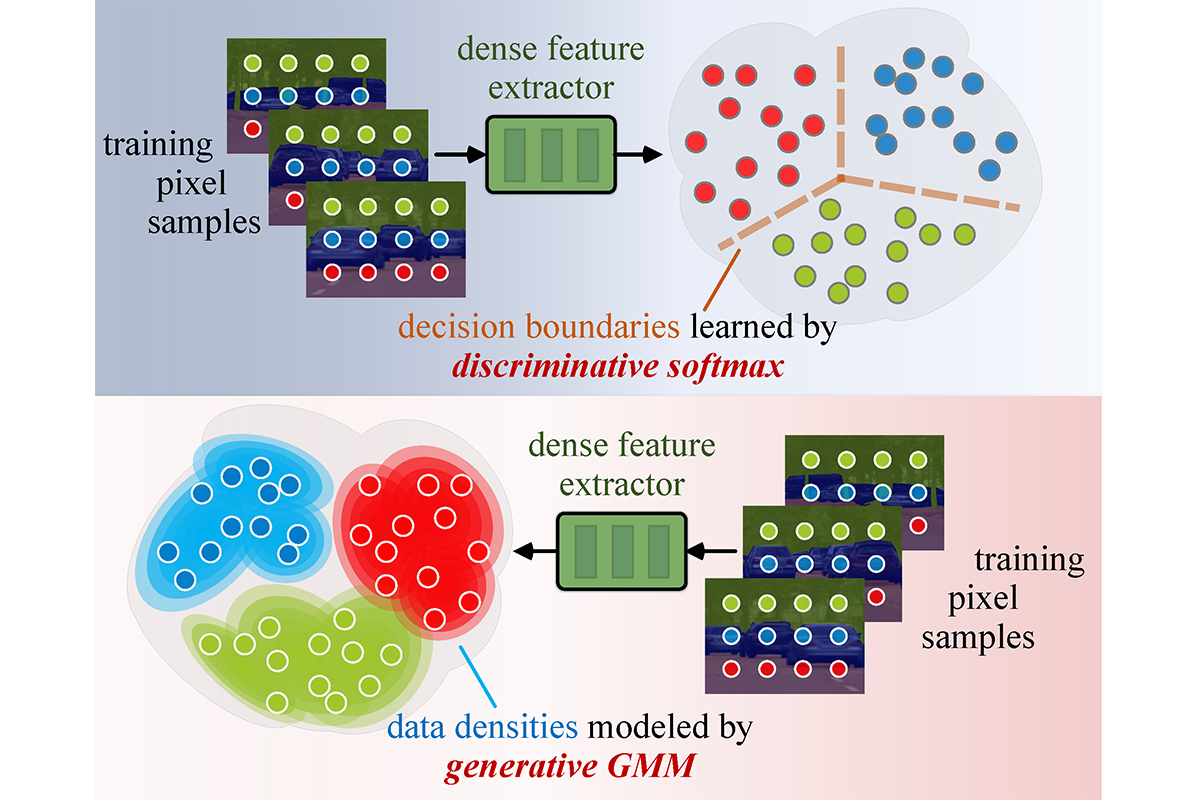
Chen Liang, Wenguan Wang, Jiaxu Miao, Yi Yang NeurIPS, 2022 (Spotlight) arXiv / OpenReview / video (1min) / video (5min) / code We propose GMMSeg, a new family of segmentation models that rely on a dense generative classifier. GMMSeg is the first semantic segmentation method that reports promising results on both closed-set and open-world scenarios by using a single model instance. |


|
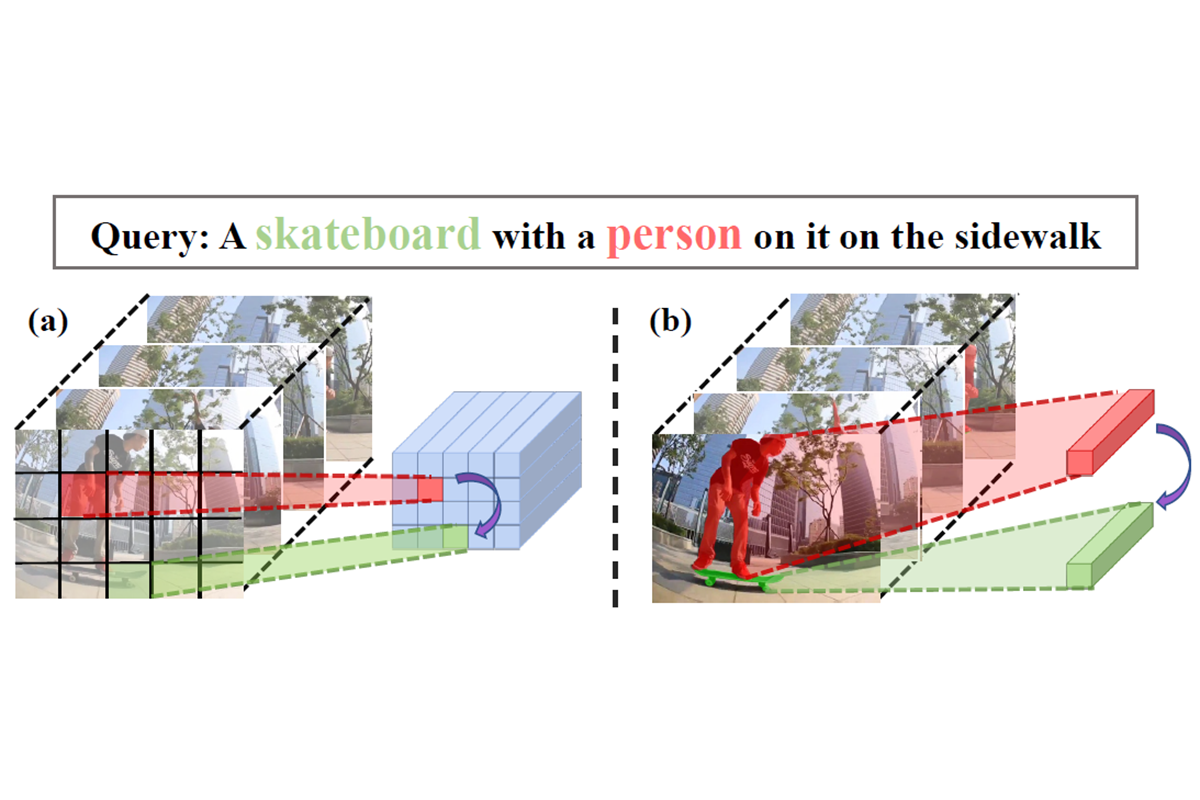
Chen Liang, Wenguan Wang, Tianfei Zhou, Yi Yang CVPR, 2022 arXiv / dataset / video / code A pilot work towards reasoning-beyond-observation in visual machine intelligence. |
|
Chen Liang, Yu Wu, Tianfei Zhou, Wenguan Wang, Zongxin Yang, Yunchao Wei, Yi Yang CVPR workshop, 2021 (Short Technical Report) arXiv / video Champion solution in The 3rd Large-scale Video Object Segmentation Challenge: Referring Video Object Segmentation Track. |

|
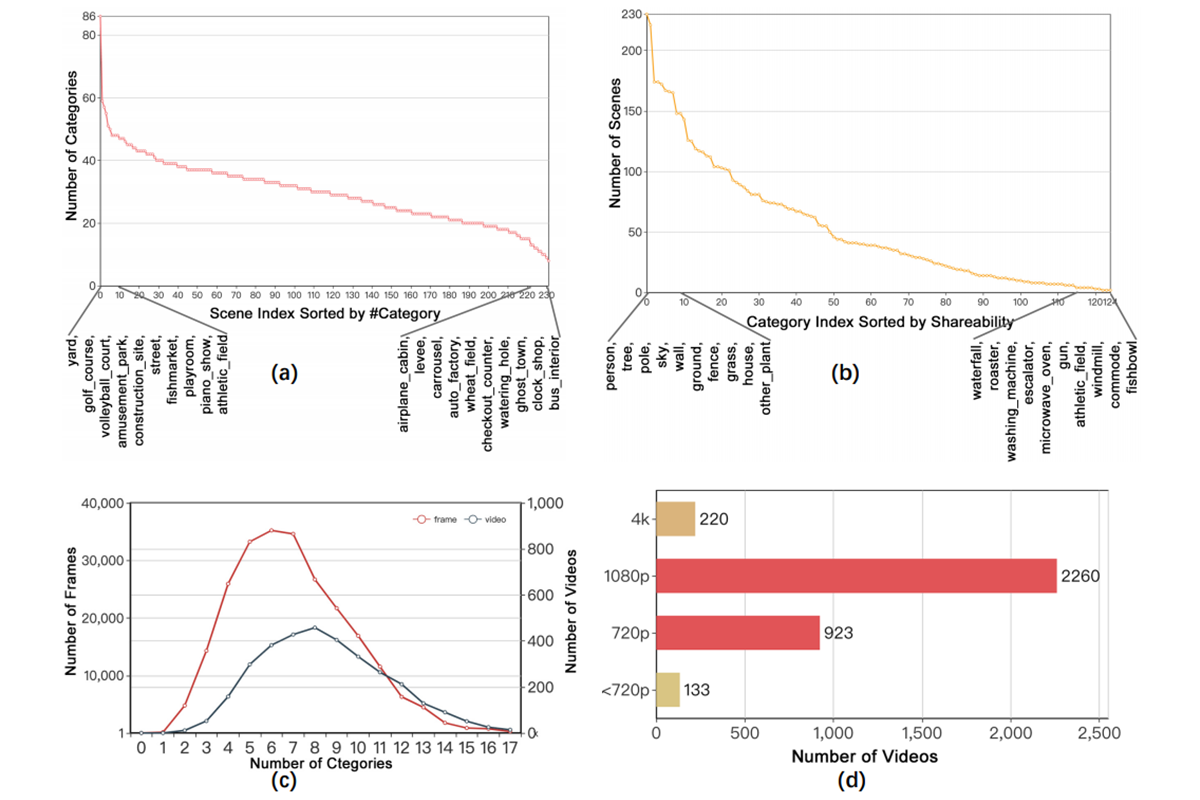
Jiaxu Miao, Yunchao Wei, Yu Wu, Chen Liang, Guangrui Li, Yi Yang CVPR, 2021 pdf / dataset / video / code A new large-scale dataset for practical video scene parsing. |
|
Code stolen from Jon Barron 0v0. |